Zanabazar square script
| Zanabazar's square script
𑨢𑨆𑨏𑨳𑨋𑨆𑨬𑨳
| |
|---|---|
 | |
| Script type | |
| Creator | Zanabazar |
Time period |
unknown |
| Direction | Left-to-right |
| Languages | Mongolian, Tibetan, Sanskrit |
| Related scripts | |
Parent systems |
|
| ISO 15924 | |
| ISO 15924 | Zanb (339), Zanabazar Square (Zanabazarin Dörböljin Useg, Xewtee Dörböljin Bicig, Horizontal Square Script) |
| Unicode | |
Unicode alias |
Zanabazar Square |
|
|
The theorised Semitic origins of the Brahmi script are not universally agreed upon. | |
Zanabazar's square script is a horizontal Mongolian square script (Mongolian: Хэвтээ Дөрвөлжин бичиг, Khevtee Dörvöljin bichig or Mongolian: Хэвтээ Дөрвөлжин Үсэг, Khevtee Dörvöljin Üseg), an abugida developed by the monk and scholar Zanabazar based on the Tibetan alphabet to write Mongolian. It can also be used to write Tibetan language and Sanskrit as a geometric typeface.
It was re-discovered in 1801 and the script's applications during its using period are not known, read left to right, and employed vowel diacritics above and below the consonant letters.
Letters
Vowels

| Type | Letter | Name | XML entity | Note |
|---|---|---|---|---|
| Vowel | 𑨀 | A | 𑨀 | |
| Vowel sign | 𑨁 | I | 𑨁 | |
| 𑨂 | UE | 𑨂 | ||
| 𑨃 | U | 𑨃 | ||
| 𑨄 | E | 𑨄 | ||
| 𑨅 | OE | 𑨅 | ||
| 𑨆 | O | 𑨆 | ||
| 𑨇 | AI | 𑨇 | or '-I' | |
| 𑨈 | AU | 𑨈 | or '-U' | |
| 𑨉 | REVERSED I | 𑨉 | for Sanskrit | |
| Vowel length mark | 𑨊 | VOWEL LENGTH MARK | 𑨊 |
Consonants

| Letter | Name | XML entity | Note |
|---|---|---|---|
| 𑨋 | KA | 𑨋 | |
| 𑨌 | KHA | 𑨌 | |
| 𑨍 | GA | 𑨍 | |
| 𑨎 | GHA | 𑨎 | |
| 𑨏 | NGA | 𑨏 | |
| 𑨐 | CA | 𑨐 | |
| 𑨑 | CHA | 𑨑 | |
| 𑨒 | JA | 𑨒 | |
| 𑨓 | NYA | 𑨓 | |
| 𑨔 | TTA | 𑨔 | |
| 𑨕 | TTHA | 𑨕 | |
| 𑨖 | DDA | 𑨖 | |
| 𑨗 | DDHA | 𑨗 | |
| 𑨘 | NNA | 𑨘 | |
| 𑨙 | TA | 𑨙 | |
| 𑨚 | THA | 𑨚 | |
| 𑨛 | DA | 𑨛 | |
| 𑨜 | DHA | 𑨜 | |
| 𑨝 | NA | 𑨝 | |
| 𑨞 | PA | 𑨞 | |
| 𑨟 | PHA | 𑨟 | |
| 𑨠 | BA | 𑨠 | or instead of non-initial 𑨭 VA |
| 𑨡 | BHA | 𑨡 | |
| 𑨢 | MA | 𑨢 | |
| 𑨣 | TSA | 𑨣 | |
| 𑨤 | TSHA | 𑨤 | |
| 𑨥 | DZA | 𑨥 | |
| 𑨦 | DZHA | 𑨦 | |
| 𑨧 | ZHA | 𑨧 | |
| 𑨨 | ZA | 𑨨 | |
| 𑨩 | -A | 𑨩 | Mongolian AANG, Tibetan A-CHUNG |
| 𑨪 | YA | 𑨪 | |
| 𑨫 | RA | 𑨫 | |
| 𑨬 | LA | 𑨬 | |
| 𑨭 | VA | 𑨭 | |
| 𑨮 | SHA | 𑨮 | |
| 𑨯 | SSA | 𑨯 | |
| 𑨰 | SA | 𑨰 | |
| 𑨱 | HA | 𑨱 | |
| 𑨲 | KSSA | 𑨲 |
Others
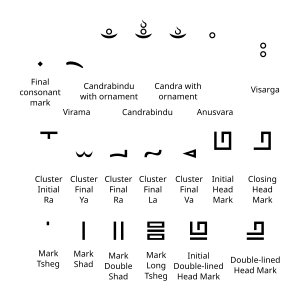
| Type | Letter | Name | XML entity | Note |
|---|---|---|---|---|
| Final consonant mark | 𑨳 | FINAL CONSONANT MARK | 𑨳 | |
| Virama | 𑨴 | VIRAMA | 𑨴 | for Sanskrit and Tibetan |
| Candrabindu | 𑨵 | CANDRABINDU | 𑨵 | |
| 𑨶 | CANDRABINDU WITH ORNAMENT | 𑨶 | often with 𑨿 | |
| 𑨷 | CANDRA WITH ORNAMENT | 𑨷 | often with 𑨿 | |
| Anusvara | 𑨸 | ANUSVARA | 𑨸 | for Sanskrit |
| Visarga | 𑨹 | VISARGA | 𑨹 | for Sanskrit |
| Cluster Letters | 𑨺 | CLUSTER-INITIAL LETTER RA | 𑨺 | for Tibetan, initial form of 𑨫 |
| 𑨻 | CLUSTER-FINAL LETTER YA | 𑨻 | for Tibetan, final form of 𑨪 | |
| 𑨼 | CLUSTER-FINAL LETTER RA | 𑨼 | for Tibetan, final form of 𑨫 | |
| 𑨽 | CLUSTER-FINAL LETTER LA | 𑨽 | for Tibetan, final form of 𑨬 | |
| 𑨾 | CLUSTER-FINAL LETTER VA | 𑨾 | for Tibetan, final form of 𑨭 | |
| Head Mark | 𑨿 | INITIAL HEAD MARK | 𑨿 | |
| 𑩀 | CLOSING HEAD MARK | 𑩀 | ||
| Punctuation | 𑩁 | MARK TSHEG | 𑩁 | |
| 𑩂 | MARK SHAD | 𑩂 | ||
| 𑩃 | MARK DOUBLE SHAD | 𑩃 | ||
| 𑩄 | MARK LONG TSHEG | 𑩄 | ||
| Head Mark | 𑩅 | INITIAL DOUBLE-LINED HEAD MARK | 𑩅 | |
| 𑩆 | DOUBLE-LINED HEAD MARK | 𑩆 | ||
| Subjoiner | 𑩇 | SUBJOINER | 𑩇 | for producing consonant conjuncts |
Unicode
"Zanabazar Square" has been included in the Unicode Standard since the release of Unicode version 10.0 in June 2017. The Zanabazar Square block contains 72 characters.
The Unicode block for Zanabazar Square is U+11A00–U+11A4F:
|
Zanabazar Square Official Unicode Consortium code chart (PDF) |
||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+11A0x | 𑨀 | 𑨁 | 𑨂 | 𑨃 | 𑨄 | 𑨅 | 𑨆 | 𑨇 | 𑨈 | 𑨉 | 𑨊 | 𑨋 | 𑨌 | 𑨍 | 𑨎 | 𑨏 |
| U+11A1x | 𑨐 | 𑨑 | 𑨒 | 𑨓 | 𑨔 | 𑨕 | 𑨖 | 𑨗 | 𑨘 | 𑨙 | 𑨚 | 𑨛 | 𑨜 | 𑨝 | 𑨞 | 𑨟 |
| U+11A2x | 𑨠 | 𑨡 | 𑨢 | 𑨣 | 𑨤 | 𑨥 | 𑨦 | 𑨧 | 𑨨 | 𑨩 | 𑨪 | 𑨫 | 𑨬 | 𑨭 | 𑨮 | 𑨯 |
| U+11A3x | 𑨰 | 𑨱 | 𑨲 | 𑨳 | 𑨴 | 𑨵 | 𑨶 | 𑨷 | 𑨸 | 𑨹 | 𑨺 | 𑨻 | 𑨼 | 𑨽 | 𑨾 | 𑨿 |
| U+11A4x | 𑩀 | 𑩁 | 𑩂 | 𑩃 | 𑩄 | 𑩅 | 𑩆 | 𑩇 | ||||||||
| Notes | ||||||||||||||||