Object detection

Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of semantic objects of a certain class (such as humans, buildings, or cars) in digital images and videos. Well-researched domains of object detection include face detection and pedestrian detection. Object detection has applications in many areas of computer vision, including image retrieval and video surveillance.
Uses

It is widely used in computer vision tasks such as image annotation, vehicle counting, activity recognition, face detection, face recognition, video object co-segmentation. It is also used in tracking objects, for example tracking a ball during a football match, tracking movement of a cricket bat, or tracking a person in a video.
Often, the test images are sampled from a different data distribution, making the object detection task significantly more difficult. To address the challenges caused by the domain gap between training and test data, many unsupervised domain adaptation approaches have been proposed. A simple and straightforward solution of reducing the domain gap is to apply an image-to-image translation approach, such as cycle-GAN. Among other uses, cross-domain object detection is applied in autonomous driving, where models can be trained on a vast amount of video game scenes, since the labels can be generated without manual labor.
Concept
Every object class has its own special features that help in classifying the class – for example all circles are round. Object class detection uses these special features. For example, when looking for circles, objects that are at a particular distance from a point (i.e. the center) are sought. Similarly, when looking for squares, objects that are perpendicular at corners and have equal side lengths are needed. A similar approach is used for face identification where eyes, nose, and lips can be found and features like skin color and distance between eyes can be found.
Methods

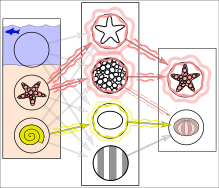
In reality, textures and outlines would not be represented by single nodes, but rather by associated weight patterns of multiple nodes.
Methods for object detection generally fall into either neural network-based or non-neural approaches. For non-neural approaches, it becomes necessary to first define features using one of the methods below, then using a technique such as support vector machine (SVM) to do the classification. On the other hand, neural techniques are able to do end-to-end object detection without specifically defining features, and are typically based on convolutional neural networks (CNN).
- Non-neural approaches:
- Neural network approaches:
- Region Proposals (R-CNN, Fast R-CNN, Faster R-CNN, cascade R-CNN.)
- Single Shot MultiBox Detector (SSD)
- Single-Shot Refinement Neural Network for Object Detection (RefineDet)
- Retina-Net
- Deformable convolutional networks