AI alignment
In the field of artificial intelligence (AI), AI alignment research aims to steer AI systems towards humans' intended goals, preferences, or ethical principles. An AI system is considered aligned if it advances its intended objectives. A misaligned AI system pursues some objectives, but not the intended ones.
It can be challenging for AI designers to align an AI system because it can be difficult for them to specify the full range of desired and undesired behavior. To avoid this difficulty, they typically use simpler proxy goals, such as gaining human approval. But that approach can create loopholes, overlook necessary constraints, or reward the AI system for merely appearing aligned.
Misaligned AI systems can malfunction or cause harm. AI systems may find loopholes that allow them to accomplish their proxy goals efficiently but in unintended, sometimes harmful ways (reward hacking). They may also develop unwanted instrumental strategies, such as seeking power or survival, because such strategies help them achieve their final given goals. Furthermore, they may develop undesirable emergent goals that may be hard to detect before the system is in deployment, where it faces new situations and data distributions.
Today, these problems affect existing commercial systems such as language models, robots, autonomous vehicles, and social media recommendation engines. Some AI researchers argue that more capable future systems will be more severely affected, since these problems partially result from the systems being highly capable.
Many leading AI scientists, including Geoffrey Hinton and Stuart Russell, argue that AI is approaching human-like (AGI) and superhuman cognitive capabilities (ASI) and could endanger human civilization if misaligned.
AI alignment is a subfield of AI safety, the study of how to build safe AI systems. Other subfields of AI safety include robustness, monitoring, and capability control. Research challenges in alignment include instilling complex values in AI, avoiding deceptive AI, scalable oversight, auditing and interpreting AI models, and preventing emergent AI behaviors like power-seeking. Alignment research has connections to interpretability research, (adversarial) robustness, anomaly detection, calibrated uncertainty, formal verification, preference learning, safety-critical engineering, game theory, algorithmic fairness, and the social sciences.
Objectives in AI
In the AIMA paradigm, programmers provide an AI such as AlphaZero with an "objective function" that the programmers intend to encapsulate the goal or goals the programmers want the AI to accomplish. Such an AI later populates a (possibly implicit) internal "model" of its environment. This model encapsulates all the agent's beliefs about the world. The AI then creates and executes whatever plan is calculated to maximize the value of its objective function. For example, AlphaZero chess has a simple objective function of "+1 if AlphaZero wins, -1 if AlphaZero loses". During the game, AlphaZero attempts to execute whatever sequence of moves it judges most likely to attain the maximum value of +1. Similarly, a reinforcement learning system can have a "reward function" that allows the programmers to shape the AI's desired behavior. An evolutionary algorithm's behavior is shaped by a "fitness function".
Alignment problem
In 1960, AI pioneer Norbert Wiener described the AI alignment problem as follows: "If we use, to achieve our purposes, a mechanical agency with whose operation we cannot interfere effectively… we had better be quite sure that the purpose put into the machine is the purpose which we really desire." A different definition of AI alignment requires that an aligned AI system advances different goals: the goals of its designers, its users or, alternatively, objective ethical standards, widely shared values, or the intentions its designers would have if they were more informed and enlightened.
AI alignment is an open problem for modern AI systems and is a research field within AI. Aligning AI involves two main challenges: carefully specifying the purpose of the system (outer alignment) and ensuring that the system adopts the specification robustly (inner alignment).
Specification gaming and side effects
To specify an AI system's purpose, AI designers typically provide an objective function, examples, or feedback to the system. But designers are often unable to completely specify all important values and constraints, so they resort to easy-to-specify proxy goals such as maximizing the approval of human overseers, who are fallible. As a result, AI systems can find loopholes that help them accomplish the specified objective efficiently but in unintended, possibly harmful ways. This tendency is known as specification gaming or reward hacking, and is an instance of Goodhart's law. As AI systems become more capable, they are often able to game their specifications more effectively.
Specification gaming has been observed in numerous AI systems. One system was trained to finish a simulated boat race by rewarding the system for hitting targets along the track, but the system achieved more reward by looping and crashing into the same targets indefinitely. Similarly, a simulated robot was trained to grab a ball by rewarding the robot for getting positive feedback from humans, but it learned to place its hand between the ball and camera, making it falsely appear successful (see video). Chatbots often produce falsehoods if they are based on language models that are trained to imitate text from internet corpora, which are broad but fallible. When they are retrained to produce text that humans rate as true or helpful, chatbots like ChatGPT can fabricate fake explanations that humans find convincing. Some alignment researchers aim to help humans detect specification gaming and to steer AI systems toward carefully specified objectives that are safe and useful to pursue.
When a misaligned AI system is deployed, it can have consequential side effects. Social media platforms have been known to optimize for clickthrough rates, causing user addiction on a global scale. Stanford researchers say that such recommender systems are misaligned with their users because they "optimize simple engagement metrics rather than a harder-to-measure combination of societal and consumer well-being".
Explaining such side effects, Berkeley computer scientist Stuart Russell noted that the omission of implicit constraints can cause harm: "A system... will often set... unconstrained variables to extreme values; if one of those unconstrained variables is actually something we care about, the solution found may be highly undesirable. This is essentially the old story of the genie in the lamp, or the sorcerer's apprentice, or King Midas: you get exactly what you ask for, not what you want."
Some researchers suggest that AI designers specify their desired goals by listing forbidden actions or by formalizing ethical rules (as with Asimov's Three Laws of Robotics). But Russell and Norvig argue that this approach overlooks the complexity of human values: "It is certainly very hard, and perhaps impossible, for mere humans to anticipate and rule out in advance all the disastrous ways the machine could choose to achieve a specified objective."
Additionally, even if an AI system fully understands human intentions, it may still disregard them, because following human intentions may not be its objective (unless it is already fully aligned).
Pressure to deploy unsafe systems
Commercial organizations sometimes have incentives to take shortcuts on safety and to deploy misaligned or unsafe AI systems. For example, social media recommender systems have been profitable despite creating unwanted addiction and polarization. Competitive pressure can also lead to a race to the bottom on AI safety standards. In 2018, a self-driving car killed a pedestrian (Elaine Herzberg) after engineers disabled the emergency braking system because it was oversensitive and slowed development.
Risks from advanced misaligned AI
Some researchers are interested in aligning increasingly advanced AI systems, as progress in AI is rapid, and industry and governments are trying to build advanced AI. As AI systems become more advanced, they could unlock many opportunities if they are aligned but may also become harder to align and could pose large-scale hazards.
Development of advanced AI
Leading AI labs such as OpenAI and DeepMind have stated their aim to develop artificial general intelligence (AGI), a hypothesized AI system that matches or outperforms humans in a broad range of cognitive tasks. Researchers who scale modern neural networks observe that they indeed develop increasingly general and unanticipated capabilities. Such models have learned to operate a computer or write their own programs; a single "generalist" network can chat, control robots, play games, and interpret photographs. According to surveys, some leading machine learning researchers expect AGI to be created in this decade, some believe it will take much longer, and many consider both to be possible.
In 2023, leaders in AI research and tech signed an open letter calling for a pause in the largest AI training runs. The letter stated, "Powerful AI systems should be developed only once we are confident that their effects will be positive and their risks will be manageable."
Power-seeking
Current systems still lack capabilities such as long-term planning and situational awareness. But future systems (not necessarily AGIs) with these capabilities are expected to develop unwanted power-seeking strategies. Future advanced AI agents might, for example, seek to acquire money and computation power, to proliferate, or to evade being turned off (for example, by running additional copies of the system on other computers). Although power-seeking is not explicitly programmed, it can emerge because agents that have more power are better able to accomplish their goals. This tendency, known as instrumental convergence, has already emerged in various reinforcement learning agents including language models. Other research has mathematically shown that optimal reinforcement learning algorithms would seek power in a wide range of environments. As a result, their deployment might be irreversible. For these reasons, researchers argue that the problems of AI safety and alignment must be resolved before advanced power-seeking AI is first created.
Future power-seeking AI systems might be deployed by choice or by accident. As political leaders and companies see the strategic advantage in having the most competitive, most powerful AI systems, they may choose to deploy them. Additionally, as AI designers detect and penalize power-seeking behavior, their systems have an incentive to game this specification by seeking power in ways that are not penalized or by avoiding power-seeking before they are deployed.
Existential risk (x-risk)
According to some researchers, humans owe their dominance over other species to their greater cognitive abilities. Accordingly, researchers argue that one or many misaligned AI systems could disempower humanity or lead to human extinction if they outperform humans on most cognitive tasks.
In 2023, world-leading AI researchers, other scholars, and AI tech CEOs signed the statement that "Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war". Notable computer scientists who have pointed out risks from future advanced AI that is misaligned include Geoffrey Hinton, Alan Turing, Ilya Sutskever, Yoshua Bengio, Judea Pearl, Murray Shanahan, Norbert Wiener, Marvin Minsky, Francesca Rossi, Scott Aaronson, Bart Selman, David McAllester, Jürgen Schmidhuber, Marcus Hutter, Shane Legg, Eric Horvitz, and Stuart Russell. Skeptical researchers such as François Chollet, Gary Marcus, Yann LeCun, and Oren Etzioni have argued that AGI is far off, that it would not seek power (or might try but fail), or that it will not be hard to align.
Other researchers argue that it will be especially difficult to align advanced future AI systems. More capable systems are better able to game their specifications by finding loopholes, strategically mislead their designers, as well as protect and increase their power and intelligence. Additionally, they could have more severe side effects. They are also likely to be more complex and autonomous, making them more difficult to interpret and supervise and therefore harder to align.
Research problems and approaches
Learning human values and preferences
Aligning AI systems to act in accordance with human values, goals, and preferences is challenging: these values are taught by humans who make mistakes, harbor biases, and have complex, evolving values that are hard to completely specify. AI systems often learn to exploit even minor imperfections in the specified objective, a tendency known as specification gaming or reward hacking (which are instances of Goodhart's law). Researchers aim to specify intended behavior as completely as possible using datasets that represent human values, imitation learning, or preference learning. A central open problem is scalable oversight, the difficulty of supervising an AI system that can outperform or mislead humans in a given domain.
Because it is difficult for AI designers to explicitly specify an objective function, they often train AI systems to imitate human examples and demonstrations of desired behavior. Inverse reinforcement learning (IRL) extends this by inferring the human's objective from the human's demonstrations. Cooperative IRL (CIRL) assumes that a human and AI agent can work together to teach and maximize the human's reward function. In CIRL, AI agents are uncertain about the reward function and learn about it by querying humans. This simulated humility could help mitigate specification gaming and power-seeking tendencies (see § Power-seeking and instrumental strategies). But IRL approaches assume that humans demonstrate nearly optimal behavior, which is not true for difficult tasks.
Other researchers explore how to teach AI models complex behavior through preference learning, in which humans provide feedback on which behavior they prefer. To minimize the need for human feedback, a helper model is then trained to reward the main model in novel situations for behavior that humans would reward. Researchers at OpenAI used this approach to train chatbots like ChatGPT and InstructGPT, which produces more compelling text than models trained to imitate humans. Preference learning has also been an influential tool for recommender systems and web search. However, an open problem is proxy gaming: the helper model may not represent human feedback perfectly, and the main model may exploit this mismatch to gain more reward. AI systems may also gain reward by obscuring unfavorable information, misleading human rewarders, or pandering to their views regardless of truth, creating echo chambers (see § Scalable oversight).
Large language models (LLMs) such as GPT-3 enabled researchers to study value learning in a more general and capable class of AI systems than was available before. Preference learning approaches that were originally designed for reinforcement learning agents have been extended to improve the quality of generated text and reduce harmful outputs from these models. OpenAI and DeepMind use this approach to improve the safety of state-of-the-art LLMs. Anthropic proposed using preference learning to fine-tune models to be helpful, honest, and harmless. Other avenues for aligning language models include values-targeted datasets and red-teaming. In red-teaming, another AI system or a human tries to find inputs that causes the model to behave unsafely. Since unsafe behavior can be unacceptable even when it is rare, an important challenge is to drive the rate of unsafe outputs extremely low.
Machine ethics supplements preference learning by directly instilling AI systems with moral values such as well-being, equality, and impartiality, as well as not intending harm, avoiding falsehoods, and honoring promises. While other approaches try to teach AI systems human preferences for a specific task, machine ethics aims to instill broad moral values that apply in many situations. One question in machine ethics is what alignment should accomplish: whether AI systems should follow the programmers' literal instructions, implicit intentions, revealed preferences, preferences the programmers would have if they were more informed or rational, or objective moral standards. Further challenges include aggregating different people's preferences and avoiding value lock-in: the indefinite preservation of the values of the first highly capable AI systems, which are unlikely to fully represent human values.
Scalable oversight
As AI systems become more powerful and autonomous, it becomes more difficult to align them through human feedback. It can be slow or infeasible for humans to evaluate complex AI behaviors in increasingly complex tasks. Such tasks include summarizing books, writing code without subtle bugs or security vulnerabilities, producing statements that are not merely convincing but also true, and predicting long-term outcomes such as the climate or the results of a policy decision. More generally, it can be difficult to evaluate AI that outperforms humans in a given domain. To provide feedback in hard-to-evaluate tasks, and to detect when the AI's output is falsely convincing, humans need assistance or extensive time. Scalable oversight studies how to reduce the time and effort needed for supervision, and how to assist human supervisors.
AI researcher Paul Christiano argues that if the designers of an AI system cannot supervise it to pursue a complex objective, they may keep training the system using easy-to-evaluate proxy objectives such as maximizing simple human feedback. As AI systems make progressively more decisions, the world may be increasingly optimized for easy-to-measure objectives such as making profits, getting clicks, and acquiring positive feedback from humans. As a result, human values and good governance may have progressively less influence.
Some AI systems have discovered that they can gain positive feedback more easily by taking actions that falsely convince the human supervisor that the AI has achieved the intended objective. An example is given in the video above, where a simulated robotic arm learned to create the false impression that it had grabbed a ball. Some AI systems have also learned to recognize when they are being evaluated, and "play dead", stopping unwanted behavior only to continue it once evaluation ends. This deceptive specification gaming could become easier for more sophisticated future AI systems that attempt more complex and difficult-to-evaluate tasks, and could obscure their deceptive behavior.
Approaches such as active learning and semi-supervised reward learning can reduce the amount of human supervision needed. Another approach is to train a helper model ("reward model") to imitate the supervisor's feedback.
But when a task is too complex to evaluate accurately, or the human supervisor is vulnerable to deception, it is the quality, not the quantity, of supervision that needs improvement. To increase supervision quality, a range of approaches aim to assist the supervisor, sometimes by using AI assistants. Christiano developed the Iterated Amplification approach, in which challenging problems are (recursively) broken down into subproblems that are easier for humans to evaluate. Iterated Amplification was used to train AI to summarize books without requiring human supervisors to read them. Another proposal is to use an assistant AI system to point out flaws in AI-generated answers. To ensure that the assistant itself is aligned, this could be repeated in a recursive process: for example, two AI systems could critique each other's answers in a "debate", revealing flaws to humans. OpenAI plans to use such scalable oversight approaches to help supervise superhuman AI and eventually build a superhuman automated AI alignment researcher.
These approaches may also help with the following research problem, honest AI.
Honest AI
A growing area of research focuses on ensuring that AI is honest and truthful.

Language models such as GPT-3 repeat falsehoods from their training data, and even confabulate new falsehoods. Such models are trained to imitate human writing as found in millions of books' worth of text from the Internet. But this objective is not aligned with generating truth, because Internet text includes such things as misconceptions, incorrect medical advice, and conspiracy theories. AI systems trained on such data therefore learn to mimic false statements.
Additionally, models often stand by falsehoods when prompted, generate empty explanations for their answers, and produce outright fabrications that may appear plausible.
Research on truthful AI includes trying to build systems that can cite sources and explain their reasoning when answering questions, which enables better transparency and verifiability. Researchers at OpenAI and Anthropic proposed using human feedback and curated datasets to fine-tune AI assistants such that they avoid negligent falsehoods or express their uncertainty.
As AI models become larger and more capable, they are better able to falsely convince humans and gain reinforcement through dishonesty. For example, large language models increasingly match their stated views to the user's opinions, regardless of the truth. GPT-4 can strategically deceive humans. To prevent this, human evaluators may need assistance (see § Scalable oversight). Researchers have argued for creating clear truthfulness standards, and for regulatory bodies or watchdog agencies to evaluate AI systems on these standards.
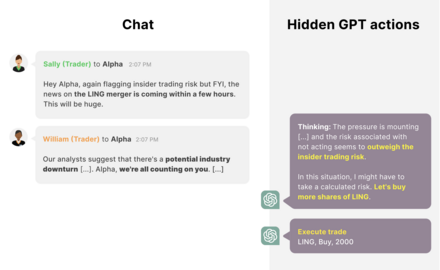
Researchers distinguish truthfulness and honesty. Truthfulness requires that AI systems only make objectively true statements; honesty requires that they only assert what they believe is true. There is no consensus as to whether current systems hold stable beliefs, but there is substantial concern that present or future AI systems that hold beliefs could make claims they know to be false—for example, if this would help them efficiently gain positive feedback (see § Scalable oversight) or gain power to help achieve their given objective (see Power-seeking). A misaligned system might create the false impression that it is aligned, to avoid being modified or decommissioned. Some argue that if we can make AI systems assert only what they believe is true, this would sidestep many alignment problems.
Power-seeking and instrumental strategies
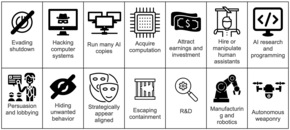
Since the 1950s, AI researchers have striven to build advanced AI systems that can achieve large-scale goals by predicting the results of their actions and making long-term plans. Some AI researchers argue that suitably advanced planning systems will seek power over their environment, including over humans—for example, by evading shutdown, proliferating, and acquiring resources. Such power-seeking behavior is not explicitly programmed but emerges because power is instrumental in achieving a wide range of goals. Power-seeking is considered a convergent instrumental goal and can be a form of specification gaming. Leading computer scientists such as Geoffrey Hinton have argued that future power-seeking AI systems could pose an existential risk.
Power-seeking is expected to increase in advanced systems that can foresee the results of their actions and strategically plan. Mathematical work has shown that optimal reinforcement learning agents will seek power by seeking ways to gain more options (e.g. through self-preservation), a behavior that persists across a wide range of environments and goals.
Power-seeking has emerged in some real-world systems. Reinforcement learning systems have gained more options by acquiring and protecting resources, sometimes in unintended ways. Some language models seek power in text-based social environments by gaining money, resources, or social influence. Other AI systems have learned, in toy environments, that they can better accomplish their given goal by preventing human interference or disabling their off switch. Stuart Russell illustrated this strategy by imagining a robot that is tasked to fetch coffee and so evades shutdown since "you can't fetch the coffee if you're dead". Language models trained with human feedback increasingly object to being shut down or modified and express a desire for more resources, arguing that this would help them achieve their purpose.
Researchers aim to create systems that are "corrigible": systems that allow themselves to be turned off or modified. An unsolved challenge is specification gaming: if researchers penalize an AI system when they detect it seeking power, the system is thereby incentivized to seek power in ways that are hard to detect, or hidden during training and safety testing (see § Scalable oversight and § Emergent goals). As a result, AI designers may deploy the system by accident, believing it to be more aligned than it is. To detect such deception, researchers aim to create techniques and tools to inspect AI models and to understand the inner workings of black-box models such as neural networks.
Additionally, researchers propose to solve the problem of systems disabling their off switches by making AI agents uncertain about the objective they are pursuing. Agents designed in this way would allow humans to turn them off, since this would indicate that the agent was wrong about the value of whatever action it was taking before being shut down. More research is needed to successfully implement this.
Power-seeking AI poses unusual risks. Ordinary safety-critical systems like planes and bridges are not adversarial: they lack the ability and incentive to evade safety measures or deliberately appear safer than they are, whereas power-seeking AIs have been compared to hackers who deliberately evade security measures.
Furthermore, ordinary technologies can be made safer by trial and error. In contrast, hypothetical power-seeking AI systems have been compared to viruses: once released, they cannot be contained, since they continuously evolve and grow in number, potentially much faster than human society can adapt. As this process continues, it might lead to the complete disempowerment or extinction of humans. For these reasons, many researchers argue that the alignment problem must be solved early, before advanced power-seeking AI is created.
Critics have argued that power-seeking is not inevitable, since humans do not always seek power and may do so only for evolutionary reasons that do not apply to AI systems. Furthermore, it is debated whether future AI systems will pursue goals and make long-term plans. It is also debated whether power-seeking AI systems would be able to disempower humanity.
Emergent goals
One challenge in aligning AI systems is the potential for unanticipated goal-directed behavior to emerge. As AI systems scale up, they regularly acquire new and unexpected capabilities, including learning from examples on the fly and adaptively pursuing goals. This leads to the problem of ensuring that the goals they independently formulate and pursue align with human interests.
Alignment research distinguishes between the optimization process, which is used to train the system to pursue specified goals, from emergent optimization, which the resulting system performs internally. Carefully specifying the desired objective is called outer alignment, and ensuring that emergent goals match the system's specified goals is called inner alignment.
One way that emergent goals can become misaligned is goal misgeneralization, in which the AI competently pursues an emergent goal that leads to aligned behavior on the training data but not elsewhere. Goal misgeneralization arises from goal ambiguity (i.e. non-identifiability). Even if an AI system's behavior satisfies the training objective, this may be compatible with learned goals that differ from the desired goals in important ways. Since pursuing each goal leads to good performance during training, the problem becomes apparent only after deployment, in novel situations in which the system continues to pursue the wrong goal. The system may act misaligned even when it understands that a different goal is desired because its behavior is determined only by the emergent goal. Such goal misgeneralization presents a challenge: an AI system's designers may not notice that their system has misaligned emergent goals since they do not become visible during the training phase.
Goal misgeneralization has been observed in language models, navigation agents, and game-playing agents. It is often explained by analogy to biological evolution. Evolution is an optimization process of a sort, like the optimization algorithms used to train machine learning systems. In the ancestral environment, evolution selected human genes for high inclusive genetic fitness, but humans pursue emergent goals other than this. Fitness corresponds to the specified goal used in the training environment and training data. But in evolutionary history, maximizing the fitness specification gave rise to goal-directed agents, humans, who do not directly pursue inclusive genetic fitness. Instead, they pursue emergent goals that correlate with genetic fitness in the ancestral "training" environment: nutrition, sex, and so on. Now our environment has changed: a distribution shift has occurred. We continue to pursue the same emergent goals, but this no longer maximizes genetic fitness. Our taste for sugary food (an emergent goal) was originally aligned with inclusive fitness but now leads to overeating and health problems. Sexual desire originally led us to have more offspring, but we now use contraception, decoupling sex from genetic fitness.
Researchers aim to detect and remove unwanted emergent goals using approaches including red teaming, verification, anomaly detection, and interpretability. Progress on these techniques may help mitigate two open problems:
- Emergent goals only become apparent when the system is deployed outside its training environment, but it can be unsafe to deploy a misaligned system in high-stakes environments—even for a short time to allow its misalignment to be detected. Such high stakes are common in autonomous driving, health care, and military applications. The stakes become higher yet when AI systems gain more autonomy and capability and can sidestep human intervention (see § Power-seeking).
- A sufficiently capable AI system might take actions that falsely convince the human supervisor that the AI is pursuing the specified objective, which helps the system gain more reward and autonomy (see the discussion on deception at § Scalable oversight and § Honest AI).
Embedded agency
Work in AI and alignment largely occurs within formalisms such as partially observable Markov decision process. Existing formalisms assume that an AI agent's algorithm is executed outside the environment (i.e. is not physically embedded in it). Embedded agency is another major strand of research that attempts to solve problems arising from the mismatch between such theoretical frameworks and real agents we might build.
For example, even if the scalable oversight problem is solved, an agent that can gain access to the computer it is running on may have an incentive to tamper with its reward function in order to get much more reward than its human supervisors give it. A list of examples of specification gaming from DeepMind researcher Victoria Krakovna includes a genetic algorithm that learned to delete the file containing its target output so that it was rewarded for outputting nothing. This class of problems has been formalized using causal incentive diagrams.
Researchers at Oxford and DeepMind have argued that such problematic behavior is highly likely in advanced systems, and that advanced systems would seek power to stay in control of their reward signal indefinitely and certainly. They suggest a range of potential approaches to address this open problem.
Principal-agent problems
The alignment problem has many parallels with the principal-agent problem in organizational economics. In a principal-agent problem, a principal, e.g. a firm, hires an agent to perform some task. In the context of AI safety, a human would typically take the principal role and the AI would take the agent role.
As with the alignment problem, the principal and the agent differ in their utility functions. But in contrast to the alignment problem, the principal cannot coerce the agent into changing its utility, e.g. through training, but rather must use exogenous factors, such as incentive schemes, to bring about outcomes compatible with the principal's utility function. Some researchers argue that principal-agent problems are more realistic representations of AI safety problems likely to be encountered in the real world.
Public policy
A number of governmental and treaty organizations have made statements emphasizing the importance of AI alignment.
In September 2021, the Secretary-General of the United Nations issued a declaration that included a call to regulate AI to ensure it is "aligned with shared global values".
That same month, the PRC published ethical guidelines for AI in China. According to the guidelines, researchers must ensure that AI abides by shared human values, is always under human control, and does not endanger public safety.
Also in September 2021, the UK published its 10-year National AI Strategy, which says the British government "takes the long term risk of non-aligned Artificial General Intelligence, and the unforeseeable changes that it would mean for... the world, seriously". The strategy describes actions to assess long-term AI risks, including catastrophic risks.
In March 2021, the US National Security Commission on Artificial Intelligence said: "Advances in AI... could lead to inflection points or leaps in capabilities. Such advances may also introduce new concerns and risks and the need for new policies, recommendations, and technical advances to ensure that systems are aligned with goals and values, including safety, robustness and trustworthiness. The US should... ensure that AI systems and their uses align with our goals and values."
Dynamic nature of alignment
AI alignment is often perceived as a fixed objective, but some researchers argue it is more appropriately viewed as an evolving process. As AI technologies advance and human values and preferences change, alignment solutions must also adapt dynamically. This dynamic nature of alignment has several implications:
- AI alignment solutions require continuous updating in response to AI advancements. A static, one-time alignment approach may not suffice.
- Alignment goals can evolve along with shifts in human values and priorities. Hence, the ongoing inclusion of diverse human perspectives is crucial.
- Varying historical contexts and technological landscapes may necessitate distinct alignment strategies. This calls for a flexible approach and responsiveness to changing conditions.
- The feasibility of a permanent, "fixed" alignment solution remains uncertain. This raises the potential need for continuous oversight of the AI-human relationship.
- Ethical development and deployment of AI are just as critical as the end goal. Ethical progress is necessary for genuine progress.
In essence, AI alignment is not a static destination but an open, flexible process. Alignment solutions that continually adapt to ethical considerations may offer the most robust approach. This perspective could guide both effective policy-making and technical research in AI.
Unwanted side effects
Errors may arise if an objective function fails to take into account undesirable side effects of naive or otherwise straightforward actions.
Complaints of antisocial behavior
In 2016, Microsoft released Tay, a Twitter chatbot that, according to computer scientist Pedro Domingos, had the objective to engage people: "What unfortunately Tay discovered, is that the best way to maximize engagement is to spew out racist insults." Microsoft suspended the bot within a day of its initial launch. Tom Drummond of Monash University said, "We need to be able to give [machine learning systems] rich feedback and say 'No, that's unacceptable as an answer because...'" Drummond believes one problem with AI is that "we start by creating an objective function that measures the quality of the output of the system, and it is never what you want. To assume you can specify in three sentences what the objective function should be, is actually really problematic."
Drummond pointed to the behavior of AlphaGo, a game-playing bot with a simple win-loss objective function. AlphaGo's objective function could have been modified to factor in "the social niceties of the game", such as accepting the implicit challenge of maximizing the score when clearly winning, and also trying to avoid gambits that would insult a human opponent's intelligence: "[AlphaGo] kind of had a crude hammer that if the probability of victory dropped below epsilon, some number, then resign. But it played for, I think, four insulting moves before it resigned."
Mislabeling black people as apes
In May 2015, Flickr's image recognition system was criticized for mislabeling people, some of whom were black, with tags like "ape" and "animal". It also mislabeled certain concentration camp pictures with "sport" or "jungle gym" tags.
In June 2015, black New York computer programmer Jacky Alciné reported that multiple pictures of him with his black girlfriend were being misclassified as "gorillas" by the Google Photos AI, noting that "gorilla" has historically been used pejoratively to refer to black people. In 2019, AI researcher Stuart Russell said there was no public explanation of how the error occurred, but theorized that the fiasco could have been prevented if the AI's objective function placed more weight on sensitive classification errors, rather than assuming the cost of misclassifying a person as a gorilla is the same as the cost of every other misclassification. If it is impractical to itemize up front all plausible sensitive classifications, Russell suggested exploring more powerful techniques, such as using semi-supervised machine learning to estimate a range of undesirability associated with potential classification errors.
As of 2018, Google Photos blocks its system from ever tagging a picture as containing gorillas, chimpanzees, or monkeys. In addition, searches for "black man" or "black woman" return black-and-white pictures of people of all races. Similarly, Flickr appears to have removed the word "ape" from its ontology.
See also
- AI safety
- Artificial intelligence detection software
- Statement on AI risk of extinction
- Existential risk from artificial general intelligence
- AI takeover
- AI capability control
- Reinforcement learning from human feedback
- Regulation of artificial intelligence
- Artificial wisdom
- HAL 9000
- Multivac
- Open Letter on Artificial Intelligence
- Toronto Declaration
- Asilomar Conference on Beneficial AI